
| 저자 | Sam Ainsworth et al. |
| 연도 | 2020 |
| 게재처 | IEEE S&P |
| 유형 | garbage collection |
| URL | https://ieeexplore.ieee.org/document/9152661 |
Introduction
이 논문은 C/C++에서 발생하는 Use-After-Free를 막기 위한 방법을 제안한다. 사용자가 free한 객체를 quarantine list에 저장하고, live-object traversal을 통해 quarantine 객체에 dangling pointer가 없다고 판단되면 해당 객체를 재사용할 수 있게 한다.
크기가 큰 객체는 page를 unmap하고 바로 재사용할 수 있게 하고, live-object traversal은 크기가 작은 객체만을 대상으로 함으로써 메모리 오버헤드를 줄였다. 또한, 사용자의 free를 통해 얻을 수 있는 정보를 바탕으로 live-object traversal를 수행함으로써 마찬가지로 오버헤드를 줄일 수 있었다.
SPEC CPU 2006을 가지고 평가한 결과, 성능 오버헤드는 평균 1.1X (최대 2X), 메모리 오버헤드는 평균 1.15X (최대 2X)를 보였다. 이는 실제로 사용하기에 크게 높지 않은 수치이며, 이전 연구들에 비해서도 더 낮은 수치에 해당한다.
Background
Use-After-Free
UAF 취약점은 말 그대로 free된 객체를 가리키고 있던 포인터를 사용함으로써, 다른 객체가 할당된 위치에 공격자가 원하는 값을 작성하는 공격이다.
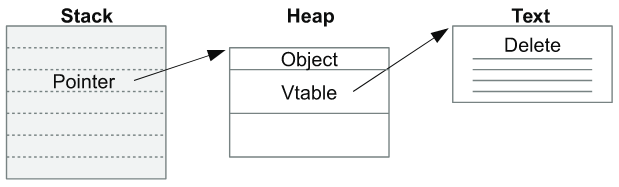
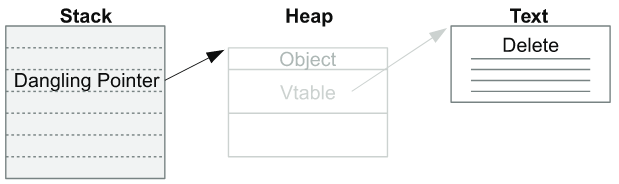
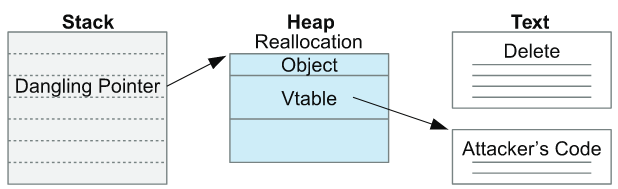
위의 그림 순서와 같이, Heap에 재할당된 객체의 값을 Dangling pointer를 통해 overwrite 함으로써 공격자가 원하는 코드를 가리키도록 만들 수 있다.
Garbage Collection
JAVA, C#, GO와 같은 high-level 언어에서는 garbage collection이 사용된다. garbage collection은 data가 자신을 가리키는 포인터가 없을 경우에만 해제되도록 하는 메커니즘이다.
C/C++에서 garbage collection을 사용하기 힘든 이유가 있다.
- 포인터와 포인터가 아닌 다른 데이터를 구별하기 어렵다.
- 모든 데이터를 포인터라고 상정하게 되면, 메모리를 제때 해제하지 못해 leak이 발생할 수 있다.
- 포인터가 숨겨질 수 있다. (XOR list, Compiler 최적화)
- 아직 해제하면 안되는 데이터가 잘못 해제될 수 있다.
MarkUs는 정확히 말하면 garbage collector는 아니다. 하지만, garbage collector에서 수행하는 marking 과정은 비슷하게 수행된다. 사용자가 해제하여 quarantine list에 존재하는 객체에 대해서는 dangling pointer가 존재하는지 확인한다.
즉, high-level 언어에서의 garbage collector처럼 참조하는 포인터가 없는 객체를 스스로 해제하진 않지만, 사용자가 해제하고자 하는 객체에 대해서는 해제해도 되는지 live-object traversal을 통해 확인한다는 것이다.
Threat Model
공격자는 메모리 할당, 해제가 가능하며, 해제된 객체에 접근이 가능함.
오직 heap UAF만을 방어 대상으로 함. (stack UAF나 heap overflow 등은 고려 대상 X)
Design
MarkUS의 구체적인 Design에 대해 하나하나 알아보자.
A. Quarantine List
MarkUs에서는 사용자의 free와 해당 청크의 reallocate를 분리하였다. 사용자가 객체를 free하면, 해당 청크는 바로 free list에 들어가지 않고 quarantine list에 먼저 들어가게 된다.
오직 이 quarantine list에 존재하는 객체만이 실제로 해제되고 재사용될 수 있다. 즉, MarkUs는 다른 garbage collector 처럼 heap에서 사용되지 않는 메모리를 알아서 정리하지 않고, 사용자가 해제하기를 원하는 메모리만 해제하는 것이다. (C/C++의 hidden pointer를 방지하기 위해)
B. Identifying Live Objects
MarkUs는 주기적으로 live-object traversal을 실행한다.
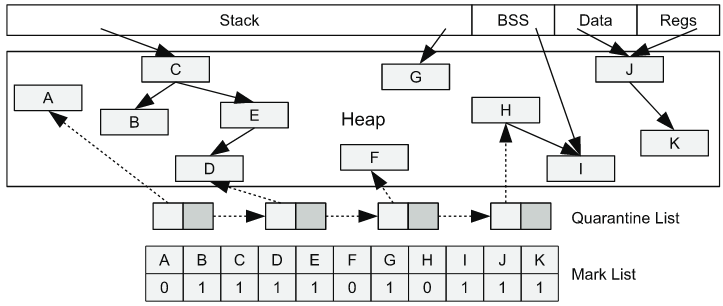
그림과 같이 Stack, BSS, Data, Register, 그리고 Heap 자체에서, 모든 data를 pointer로 가정하고 해당 포인터가 가리키는 곳을 체크한다. 이때, 특정 포인터가 가리키는 영역이 heap 영역이라면, graph traversal를 통해 recursive하게 경로를 추적한다. 이렇게 marking 과정을 마친 후, Quarantine list에 들어있는 객체를 가리키는 포인터가 존재하지 않는다면 (그림에서의 A, F, H), 해당 객체는 해제하고 재사용할 수 있다고 판단한다.
이 marking 과정은 parallel하게 진행된다. 어차피 quarantine list를 만듦으로써 비정상적인 해제는 불가능하기 때문에(quarantine list에 존재하는, 즉 사용자가 해제 요청한 객체에 대해서만 해제 가능) 제약사항은 딱히 존재하지 않고, 그저 parallel하게 진행되는 marking 과정에서 race condition만 주의하면 된다.
또한, marking 과정에서 circular reference를 방지하기 위해서, 사용자의 free시에 quarantine list에 추가할 때 객체의 값을 0으로 초기화하는 방법도 존재한다. 하지만 이로 인한 performance 오버헤드가 크기에 MarkUs에서는 이 방법을 사용하지 않고 일반적인 garbage collector(Boehm-Demers-Weiser)처럼 그저 transitively하게 poiner를 따라가는 방식을 사용한다.
C. Quarantine-List Walk
위에서 이미 많이 언급한 내용이다. 기존 garbage collector의 경우 알아서 heap에서 사용되고 있지 않은 메모리를 청소해주지만, MarkUs는 오직 quarantine List에 존재하며, Marking 과정에서 체크되지 않은 객체만을 해제한다. 단, quarantine list에 존재한다고 해서 dangling pointer에 의해 해당 객체의 값이 변경되지 않는다는 것을 보장하지는 않는다. 그래서 더욱 정확한 marking 과정이 필요한 것이다.
D. Mark Frequency
Marking 과정은 일반적인 garbage collector에서도, MarkUs에서도 꽤나 비용이 많이 드는 작업이다. 따라서 performance overhead를 줄이기 위해서 Marking 과정을 최소한으로 발생시키면서 필요할 때만 할 수 있도록 하는 것이 중요하다.
MarkUs에서는 Marking을 실행하는 기준을 다음과 같이 제시하고 있다.
💡 (qlsize – failed_frees – usize) * N > (heap_size – unmapped)
각각의 값에 대한 설명은 다음과 같다.
- qlsize : quarantine list size
- failed_frees : 이전 marking에서 free되지 못한(dangling pointer가 존재했던) 데이터 크기
- usize : quarantine list중에서 unmap된 메모리 크기 (즉, physical memory를 사용하지 않는)
- N : 사용자 설정 값, heap 크기에 영향
- heap_size : 프로세스에 할당된 heap의 크기
- unmapped : heap에서 unmap된 부분
failed_frees는 다음 marking에서 dangling pointer가 존재하지 않아서 성공적으로 해제될 수도 있다. 하지만 그렇지 않을 확률도 높기 때문에, failed_frees를 qlsize에서 빼는 것이다. 이를 통해서 marking이 너무 자주 발생하는 것을 방지하는 것이다. (performance overhead와 memory overhead 사이의 trade-off)
E. Allocator Details
allocator 자체는 Boehm-Demers-Weiser garbage collector의 allocator를 가져다가 씀.
https://en.wikipedia.org/wiki/Boehm_garbage_collector
해당 allocator는 먼저 할당하는 객체를 크기에 따라 2가지로 분류한다.
- page보다 큰 size의 객체 → 해당 객체는 page 단위로 할당되며, 할당된 page에 해당 객체만 존재하기에 해제 시에 바로 unmap이 가능하다
- page보다 작은 size의 객체 : pool strategy → 하나의 페이지에는 동일한 크기의 객체들이 한번에 할당되고 초기화된다. 그리고 페이지 당 하나의 헤더가 존재하여, 해당 헤더에서 Mark bits와 같은 메타데이터를 관리한다.
객체는 할당 시에 0으로 초기화된다. 이 과정은 이전에 남아있던(사용하지 않는) 포인터를 제거함으로써 잘못된 marking으로 인한 메모리 leak을 방지하고, 이전 heap 정보 탈취를 막는데도 효과적이다.
F. Page Unmapping
크기가 큰 할당의 경우, 유저의 해제 요청 시 page unmap을 통해 해제시켜 준다. 실제 physical page를 unmap시키기 때문에 다음 할당에서 해당 페이지가 재사용될 수 있으며, marking 과정이 생략되므로 performance 오버헤드를 줄일 수 있다.
위에서 말했듯이, MarkUs에서는 page 각각이 metadata를 가지게 되는데, 해당 metadata에 unmapped bit도 표시하게 된다. 만약 페이지 재할당 시에, 특정 페이지에 unmapped bit가 세팅되어 있으면 해당 주소에 page를 mmap하고, 그렇지 않으면 현재 heap의 끝에 새롭게 mmap하여 heap을 확장시킨다.
MarkUs가 크기가 큰 객체의 할당/해제를 대하는 것은 UAF를 막기 위한 다른 전략 중 하나인 One-time Allocator와 비슷하다고 볼 수 있다. OTA는 매 할당마다 다른 virtual page를 사용하고, alias page라는 개념을 새롭게 추가하여 한번 사용했던 alias address를 다시 사용하지 않는다는 방법을 제안한다.
MarkUs에서 크기가 큰 객체 역시 unmap된 이후 사용자가 직접적으로 해당 주소를 request하지 않는 이상 다시 사용되지 않기에 OTA와 비슷하게 보일 수 있다. 하지만 MarkUs는 그저 physical page와 virtual page의 매핑을 일대일로 유지하고, 크기가 작은 객체에 대해서는 marking 과정을 통해서 재할당을 가능하게 한다는 점에서 차이를 가진다.
G. Small-Object Block Sweeping
위에서도 언급했지만, MarkUs는 각 페이지마다 동일한 크기의 객체만을 할당하게 된다. 그런데 이 방법은 메모리 오버헤드를 크게 발생시킬 수도 있다. 만약 할당 작업이 많지 않은데 각 할당의 크기가 모두 다르다면, 각각의 객체를 위해서 크기에 맞는 페이지를 여러개 할당해야 한다. 이는 꽤나 큰 메모리 오버헤드로 이어진다.
MarkUs는 이를 해결하기 위해 다음과 같은 방법을 제안한다. 위에서 우리는 quarantine list와 marking 과정에 대해서 보았다. 다시 정리하지면, quarantine list는 사용자가 해제를 요청한 객체들로 이루어진 list이고, 이 객체들을 대상으로 marking이 진행된다.
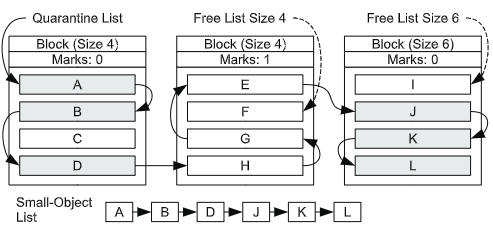
위의 그림과 같이 나타낼 수 있다. 각각의 Block은 page이며, Size는 해당 block이 저장하는 객체의 사이즈, Marks는 마킹되어 있는 객체의 수를 말한다. 여기에 Small-Object list를 추가하였다. Small-Object List에는 1) quarantine list에 있으면서, 2) 해당 객체가 속한 블럭의 Marks가 0인 객체들이 포함된다.
본격적인 Small-Object Block Sweeping의 과정을 살표보자. 이 스위핑은 특정 블럭의 Marks가 0일 때 시작된다.
- 먼저, 해당 블럭의 객체들 중 quarantine list에 속한 객체들을 Small-Object list에 추가한다.
- 다음으로, Small-Object list에 있는 객체들에 한해서, 해당 객체가 속한 블럭의 free list에 있는 객체들 역시 Small-Object list에 추가한다.
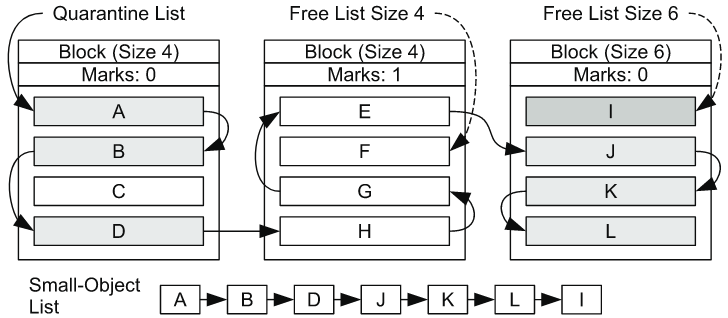
위의 그림을 보면 맨 오른쪽 블럭의 객체 I가 해당 블럭의 free list에 존재했기 때문에 이를 Small-Object list에 넣어준 것을 확인할 수 있다.
- 만약 특정 블럭의 모든 객체가 Small-Object list에 들어있다면(그림의 맨 오른쪽 블럭), 해당 블럭은 삭제되고, 다른 크기의 객체를 할당할 수 있는 블럭으로 재사용될 수 있다.
- 만약 그렇지 않다면, 기존의 quarantine list에 속한 객체들은 각 블럭의 free list에 추가해준다.
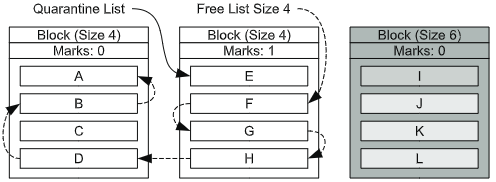
위의 그림이 Small-Object Block Sweeping 과정을 거친 후의 상태이다. 맨 오른쪽 블럭은 모든 객체가 Small-Object list에 있었기에 블럭 자체가 삭제된 상태이다. 반면, 맨 왼쪽 블럭의 경우 객체 C가 Small-Object list에 속해있지 않았기 때문에 기존에 quarantine list에 있었던 A, B, D 객체가 free list에 추가된 것을 확인할 수 있다. (가운데 블럭의 경우 Marks가 1이므로 논외)
H. Concurrency and Parallelism
MarkUs에서 marking 과정은 병렬적으로, 동시에 이루어진다. 조사할 객체들을 나눠서 여러 스레드에게 할당시키고, marking 과정은 다른 애플리케이션과 동시에 진행된다.
marking 과정이 다른 앱의 실행과 동시에 진행되는 것은 동기화 문제를 일으킬 수 있다. 마킹 과정 도중에 다른 앱에 의해 heap이나 다른 위치에 변화가 생길 수 있기 때문이다. MarkUs에서는 이 문제를 해결하기 위해 page-table의 dirty bits(페이지가 수정되었는지를 표시하는 bit)를 활용한다. marking 과정의 끝에서 이 dirty bits를 확인하여 해당 bit가 설정되어 있는 페이지에 대해서는 추가로 한번 더 확인 과정을 거치게 된다.
추가로, marking 과정에서 2번의 stop-the-world가 필요하다.
- marking 과정의 시작 : 포인터를 찾기 위한 레지스터 확인
- marking 과정의 끝 : 동시 수정으로 인한 동기화 문제 체크
이때 stop하는 시간 자체는 크지 않기에 무시해도 된다.
마지막으로, quarantine list walking 과정은 allocator의 lock 획득 하에서, 스레드 하나로 이루어진다. 이 작업의 오버헤드는 매우 적기 때문에 굳이 병렬화를 시키지 않고 스레드 하나로 수행한다.
Evaluation
evaluation environment
- CPU : Intel quad-core Haswell Core i5-4570
- memory : 16GB of DDR3 RAM
- OS : Ubuntu 16.04
SPEC CPU2006
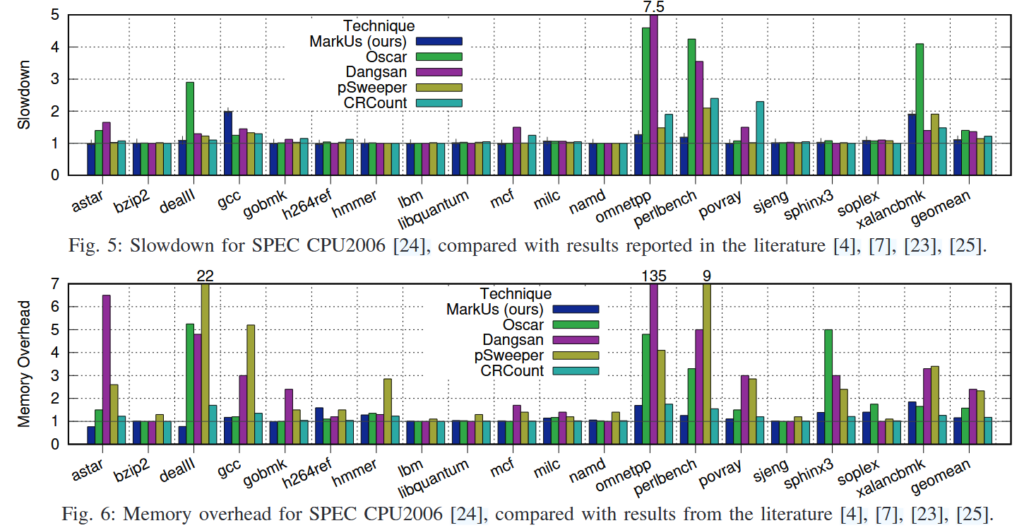
Oscar(OTA), Dangsan(pointer reference logging), pSweeper(pointer nullification), CRCount(reference counting)와의 비교 결과이다. MarkUs는 평균적으로 성능 오버헤드는 10%, 메모리 오버헤드는 16%로 다른 연구에 비해 낮은 오버헤드를 보였다. 또한, 가장 높았던 오버헤드도 성능과 메모리 각각 2배를 넘지 않았다.
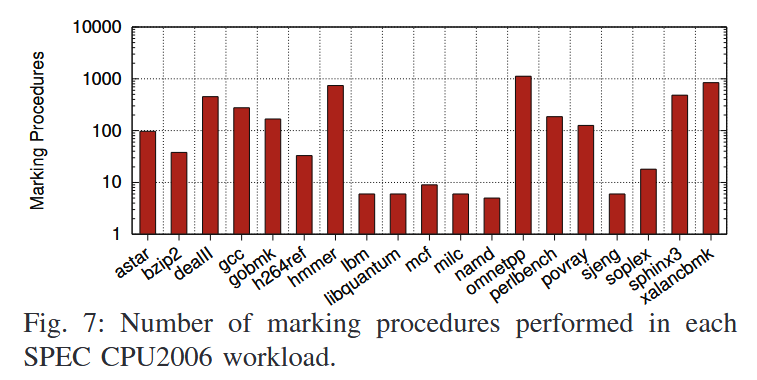
위의 그래프는 각각의 워크로드에서 marking 과정이 얼마나 실행되었는지를 나타내고 있다. 확실히 dealll, omnetpp, perlbench, xalancbmk와 같이 marking이 많이 수행된 워크로드의 성능 오버헤드가 더 높게 측정된 것을 확인할 수 있다.
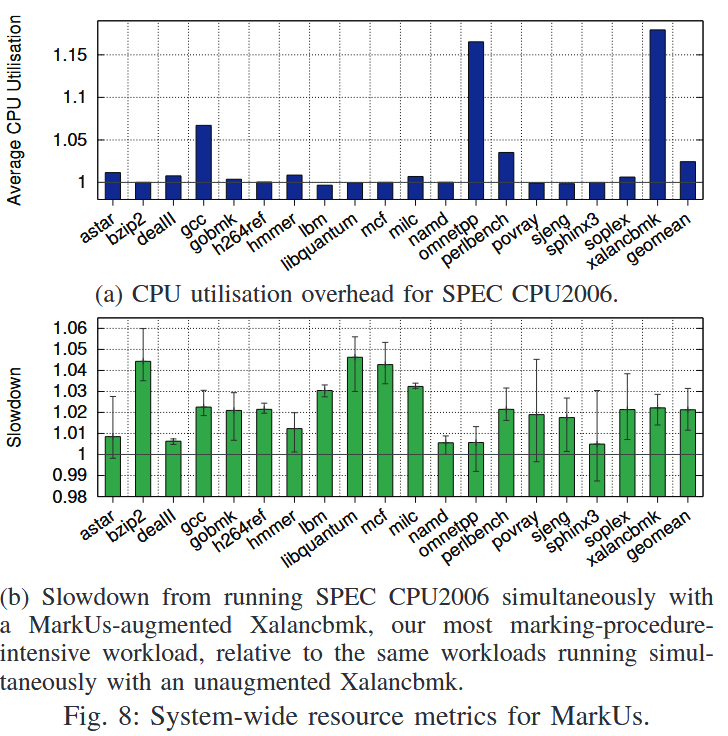
marking 과정은 multi-thread로 이루어진다. 따라서 (a) CPU 사용량을 측정해보았다. marking 과정 자체가 엄청 빈번하게 이루어지지는 않기에 CPU 사용량이 크게 증가하지는 않았다. 다음으로 (b) 할당 작업이 많은 xalancbmk를 실행시키면서 다른 워크로드들을 동시에 실행시킨 결과이다. 마찬가지로 marking이 병렬적으로 이루어지기 때문에 다른 앱과 같이 실행하더라도 성능 저하가 크지는 않다는 것을 확인할 수 있었다.
BBench
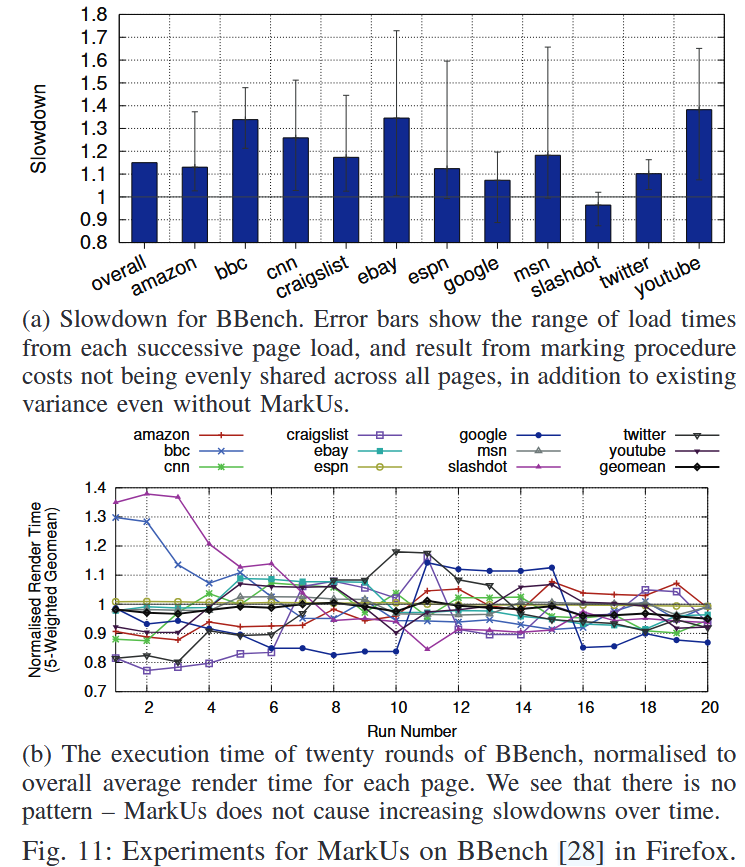
위의 그림은 복잡하며, 스레드가 많이 요구되는 브라우저 워크로드에 대한 실험 결과이다 (a). 마찬가지로 성능 저하가 평균 15%로 그렇게 크지 않은 것을 확인할 수 있었다.
또한, firefox가 웹 페이지를 로드할 때마다 시간이 달라질 수 있으므로 (b) 20번의 반복 실행을 통해 그 차이를 확인했는데, 각각의 실행에서 크게 차이가 없는 것을 확인할 수 있엇다.
Memory- Performance Tradeoffs
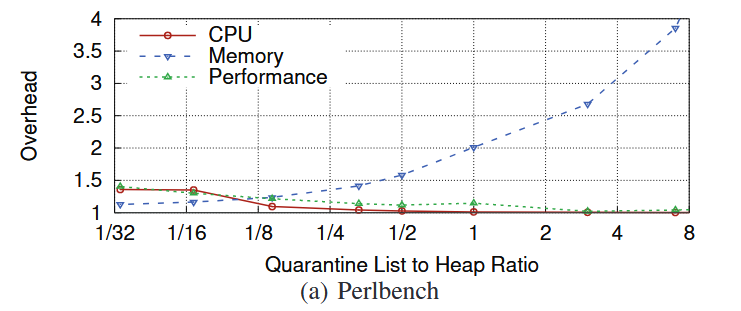
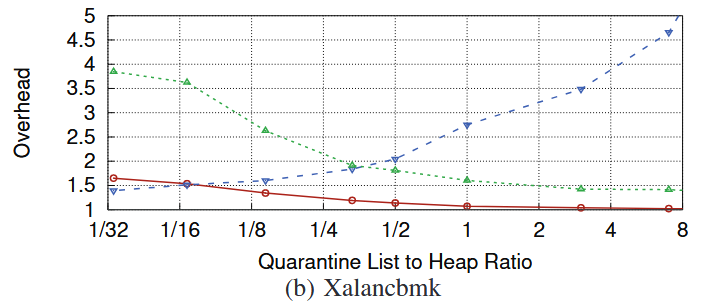
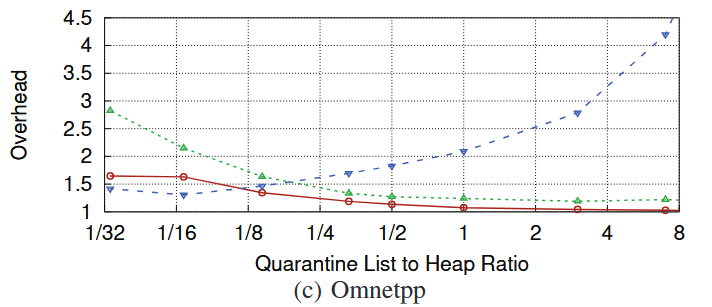
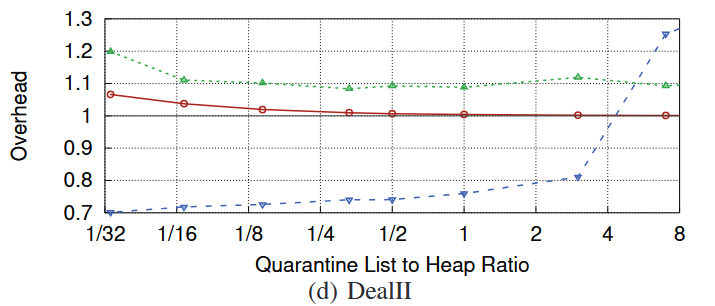
위에서 설명했듯이, MarkUs에서는 quarantine list의 크기를 사용자가 정해줄 수 있다. 이때, qlsize를 바꿔감에 따라 메모리, 성능 오버헤드의 차이가 어떻게 달라지는 지를 실험한 결과이다.
(a) Perlbench, (b) Xalancbmk, (c) Omnetpp를 보면 대체적으로 qlsize가 커질수록 성능 오버헤드는 줄어들지만, 메모리 오버헤드는 증가하는 추이를 확인할 수 있다. 이는 qlsize를 키우면 marking 과정이 발생하는 빈도가 줄어들기 때문이다. 또한 marking 과정이 multi-thread로 발생하기 때문에 CPU 사용량 역시 성능 오버헤드와 같이 줄어드는 추세임을 확인할 수 있다.
그런데 (d) DealII의 경우 예외적으로 성능 오버헤드도 크게 줄어들진 않고, 메모리 오버헤드도 엄청 증가하진 않는 결과를 보이고 있다. 이는 해당 워크로드에서 큰 사이즈의 객체를 많이 할당하기 때문에 이를 해제할 때 직접 unmap을 시켜주어 marking 과정에 주는 영향이 적기 때문이라고 볼 수 있다.
Overhead Impact of Optimisations
MarkUs에서는 오버헤드를 줄이기 위해서 여러 최적화 기법을 추가하였다. 각각의 최적화 기법이 오버헤드에 주는 영향을 실험을 진행하였다. 1. No optimisation, 2. Page unmapping, 3. Mark frequency optimisation, 4. Small-object block sweeping 순으로 각각 실험하였다.
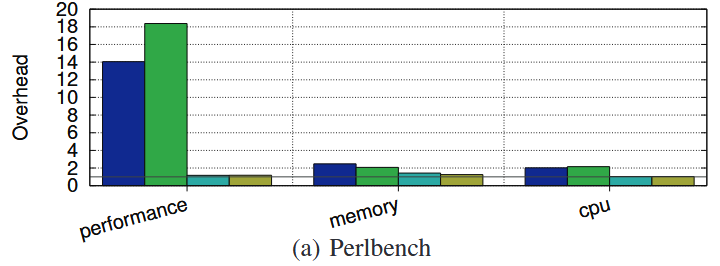
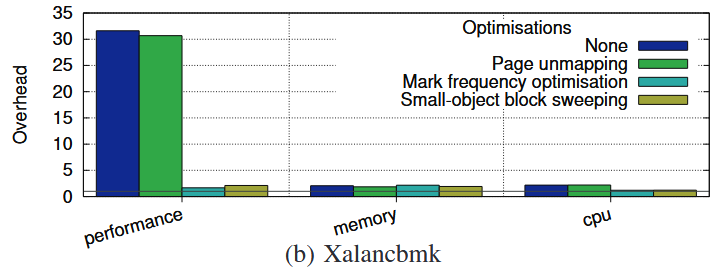
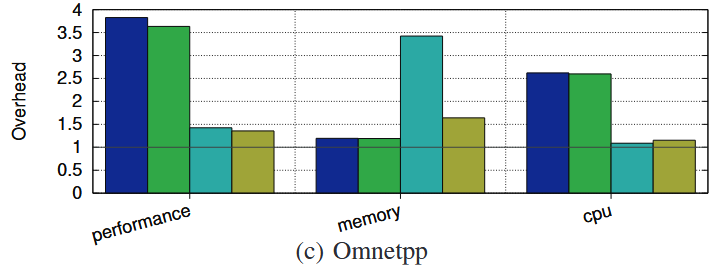
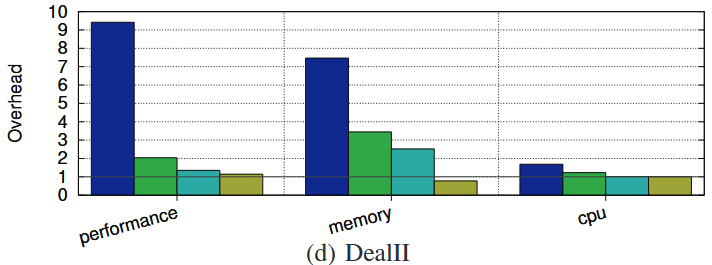
1. No optimisation
먼저 아무런 최적화를 도입하지 않았을 때의 실험 결과이다. 해당 경우는 marking 과정 진행에 대한 아무런 기준이 없기 때문에 훨씬 많이 진행되어 성능 오버헤드가 높고, (d) DealII의 경우는 큰 사이즈 객체의 할당이 많기 때문에 page unmapping이 이루어지지 않아 메모리 오버헤드도 많이 높아진 것을 확인할 수 잇다.
2. Page Unmapping
큰 사이즈 객체에 대해서 quarantine list로 넘기지 않고 해제 시 바로 unmap시켜주는 기법이다. (d) DealII의 경우 큰 사이즈 객체 할당이 많기 대문에 해당 기법을 적용시켰을 때 성능 오버헤드와 메모리 오버헤드가 많이 줄어드는 것을 확인할 수 있다.
3. Mark Frequency Optimisation
qlsize가 특정 기준을 만족하게 되면 그때에만 marking 과정을 실행하도록 하는 최적화 기법이다. 이 기법을 적용하면 확실히 marking 과정의 빈도가 확 줄어들기 대문에 성능 오버헤드를 많이 감소시키는 것을 확인할 수 있다. 반면 (c) Omnetpp의 경우를 보면 qlsize의 기준을 만족시킬 때까지 marking과 free가 발생하지 못하기 때문에 오히려 메모리 오버헤드는 증가한 것을 확인할 수 있다.
4. Small-Object Block Sweeping
작은 객체를 관리하는 block에 한해서, 만약 block 내의 모든 객체가 free or quarantine(no mark) 상태라면 해당 block을 해제하고 다른 크기의 객체 관리를 위한 블럭으로 사용 가능하게 하는 기법이다.
이 기법 역시 성능 오버헤드를 줄이고, 메모리를 재사용할 수 있게 하기 때문에 메모리 오버헤드도 줄이는 것을 확인할 수 있다. 그런데 (b) xalancbmk의 경우는 오히려 성능 오버헤드가 증가하는 것을 확인할 수 있는데, 이는 해당 최적화 기법도 결국은 마킹 과정의 마지막에 추가로 특정 요소를 체크하는 과정을 추가해야 하기 때문이다.
Allocator Overheads
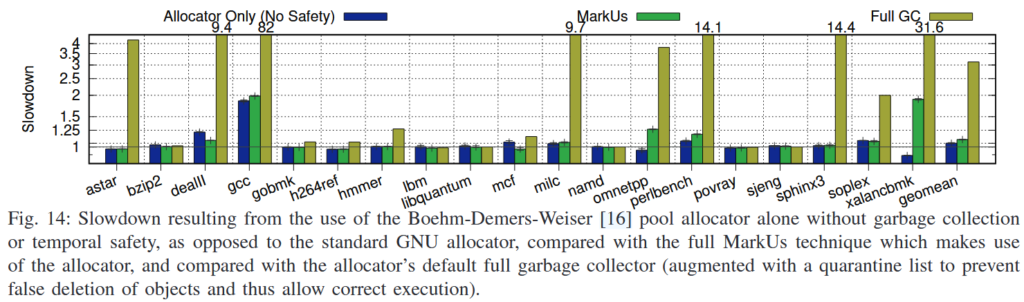
위의 그래프는 기존 pool 기반 allocator(객체를 크기 별로 관리하는 기법만 추가), MarkUs, Full Garbage-Collector 각각의 성능 오버헤드를 나타낸 것이다.
Safety를 고려하지 않은 일반 allocator의 경우 GNU allocator보다 성능이 좋은 경우도 있었고, gcc 같은 경우는 성능 오버헤드가 어느정도 발생하는 모습을 보였다.
MarkUs도 marking 과정이 추가되긴 하였지만, 기준을 추가하여 marking 과정의 빈도를 조절하였기 때문에 Allocator Only와 비교했을 때 오버헤드가 엄청 증가하진 않는 결과를 보였다.
하지만 Full Garbage-Collector의 경우 아무런 기준 없이 수시로 메모리를 체크하여 사용하지 않는 공간을 해제하는 메커니즘이기 때문에 해당 과정에 의해 성능 오버헤드가 많이 발생하는 것을 확인할 수 있었다.
Limitation
1. Sandbox environment
MarkUs에서는 보수적인 접근을 취한다. C/C++에서는 일반적인 데이터와 포인터를 구분하기 힘들기 때문에, 모든 데이터를 일단 포인터로 취급하고 marking 과정을 수행한다고 했었다.
하지만 위의 접근 방식은 또 다른 문제 상황으로 이어질 수 있다. 예를 들면, 공격자가 일반적인 정수 배열에 특정 객체의 주소를 적는다고 가정해보자. MarkUs에서 일반적인 데이터도 일단 포인터로 취급하면서 marking 과정을 수행하기에, 해당 객체가 영영 해제되지 못하고 프로그램의 메모리 사용량을 증가시킬 수 있다.
이 공격은 공격자가 권한 상승과 같이 대단한 이점을 주지는 않는다. 하지만 만약 sandbox 공간에 있는 상황이라면 sandbox의 리소스 제한을 넘어서 다른 프로그램이나 클러스터 등의 리소스를 고갈시키는 등의 공격이 가능하다.
이를 막기 위해서는 sandbox 환경에서 quarantin list나 할당된 데이터의 크기에 제한을 주거나, 혹은 고수준 언어에서 특정 구역을 integer-only로 표시하는 등의 방법을 사용할 수 있다.
2. Rewrite old links
MarkUs는 이전 객체에 저장되어 있던 작은 객체들의 link를 그대로 상속받도록 구현되어 있다. 할당 및 초기화 시에 해당 객체가 있던 구역을 자동으로 초기화시켜주지 않기 때문에, 이전의 link가 그대로 남아있을 수 있다.
만약 공격자가 객체를 할당 받아서 이전의 링크를 수정한다면, loop 구조를 만들어서 marking 과정이 끝이 안 나도록 할 수 있다. 이 공격 역시 유저의 권한을 상승시키는 정도의 위험도는 아니지만, 프로그램의 실행을 방해하고 메모리 사용량을 증가시키는 등의 영향을 줄 수 있다.
Conclusion
이 논문에서는 C/C++과 같은 저수준 언어에서 Use-After-Free를 막기 위한 MarkUs라는 allocator를 제안한다. 이는 Boehm-Demers-Weiser garbage-collector를 기반으로 mark & sweep 기법을 도입했으며, page-unmapping, Marking 빈도 최적화, Small-object 블럭 해제 후 재사용 등과 같은 최적화 기법을 도입하여 벤치마크 평가 시에 이전 연구보다 더 낮은 오버헤드를 보였다.
아래는 MarkUs를 구현한 코드를 공개한 github이다.
https://github.com/SamAinsworth/MarkUs-sp2020